Google Chrome ExtensionとAutoPagerize
2010.07.03 Saturday 22:12
django snippets というDjangoの役立ちコードを投稿するサイトがある.その中の"By Tags"において一度に20個しかタグが表示されず,実際にどんなタグがあるのか全貌を見ることができない.
全部のページを定期的に読み込んで加工することも考えたのだが,サーバを作らなくてもブラウザの中で先読みすればjavascriptで何とかできるだろうと思い,Google Chrome Extensionを作ってみることにした.
全部のページを定期的に読み込んで加工することも考えたのだが,サーバを作らなくてもブラウザの中で先読みすればjavascriptで何とかできるだろうと思い,Google Chrome Extensionを作ってみることにした.
Chrome Extensionsの作り方は Google Chrome Extensions に書かれているとおりなので詳細は割愛するが,manifest.json というファイルを作って設定をその中に記述する.今回はContent Scriptを使った.
matchesで対象サイトを(複数)設定し,そのページで読み込ませたいcssとjavascriptファイルを指定すればよい.読み込ませるファイルはmanifest.jsonと同じディレクトリに入れる.
作成したら,「拡張機能」で「デベロッパーモード」を開き,「パッケージ化されていない拡張を読み込みます」でmanifest.jsonの入ったディレクトリを指定すれば登録される.
[メモ]
拡張機能中のスクリプトにはコンソールからはアクセス出来ないので,コンソールから変数の値をチェックしたり関数を呼び出したりできない.対象サイトのページをファイルに落とすなりしてローカルのテスト用HTMLを用意し,そのヘッダファイルを書き換えてcss/jsを読み込むようにするとコンソールからアクセスできるのでデバッグしやすい.
スクリプトの中にbreakpointを設定しておくと,breakした時はそのスクリプトの変数にアクセスできる.この方法で実行経路と値のチェックができる.
printfデバッグに近い方法として console.log() を使う方法がある.引数には文字列だけでなくオブジェクトを与えることができ,オブジェクトを与えた場合にはコンソール上でその内容にツリー形式でアクセスできる.
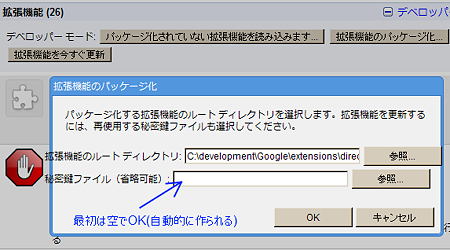
動作するようになったらパッケージを行う.「拡張機能」の「拡張機能のパッケージ化」からパッケージ化するディレクトリを指定するだけ.秘密鍵の部分は2回目以降(更新時)のみ入力する.最初は空欄にしておけば新たに生成される.
生成された *.crx をGoogle ChromeにDrag & Dropすれば普通の拡張としてインストールされる.
できたもの: djangosnippets.crx
やってること
- CSS: liタグが縦でなく横に並ぶように float: left に変更
- Javascript: Next 20< というリンクの先を読み込んでリストに追加することを400ms毎に繰り返す.
実際に動かしてみるとあまり感慨がない.(-_-)
最初に djangosnippets のタグページが使いづらいと感じた当時はタグがアルファベット順に出力されていた.しかも記号が入ったタグがあったために,ページをめくらないとまともなタグが見えない状態であった.しかし,現在はその点は改善されて使用頻度の高いタグが先頭に出るようになっている.
さて,ここまでやったところで単に次のリンクをたどるだけなら,普段使っている AutoPagerize で十分な気がしてきた.こちらは対象ページのパターン,たどるリンク,取り出す要素などを指定したSITEINFOを作るだけでOKのようだ.
SITEINFOでは対象要素をXPathで指定するようになっており,SITEINFOの作り方 ではFireBugを使うように指示されている.だが調べてみると Google ChromeのDeveloper Toolsの検索ボックスでXPathが使えるようだ.
試しにやってみる
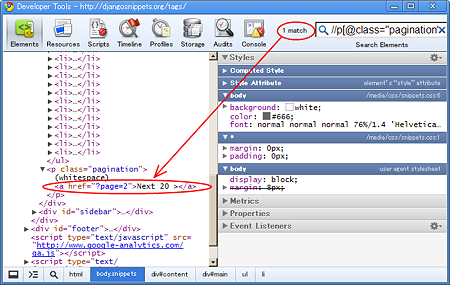
ハイライトはされないようだが,該当する要素が見つかったかどうかはmatchesを見れば良く,また見つかった要素がDOMツリーで展開される.
さて,では実際にdjangosnippets.org/tags/ を対応させてみることにする.
まず,テスト的に対応させる方法についてFirefoxについては記述があるのだが,Chromeについては記述がない.調べたところ,AutoPagerize のメインファイルである autopagerize.user.js 中の SITEINFO に直接記述して,Google Chromeを再起動すれば読み込まれることが分かった.autopagerize.user.js はC:\Documents and Settings\
この状態で http://djangosnippets.org/tags/ を開くと,次々とページがめくられてゆく.
最初,nextLinkとpageElementを誤って逆に書いてしまったのだが,その時はコンソールログにエラーメッセージが表示された.ただ,その内容は「undefinedにmatchメソッドがない」という物だったので原因が分かるまでに時間を要した.(リンクであるnextLinkの href を読み取ろうとするが,それが存在しないとundefinedとなり,次の行でエラーとなっていた.)
さて,この情報をAutoPagerizeのデータベース に登録するとみんなが使えるようになる.OpenIDを使ってログインした後に「アイテム追加」を行えば登録ができる.登録するとJSONでそのデータが直ちに利用可能となる.
ちなみに,OpenIDには便利なボタンが用意されていないので例えばGoogleの場合は https://www.google.com/accounts/o8/id のようにEndPpint URLを入力する必要がある.
さて,サーバへの登録を行っても自分のブラウザでは有効化されない.調べてみるとローカルストレージにキャッシュを持っていて,1日以上経たないと更新されない.これでは動作テストでは困るので何とか無理矢理キャッシュをクリアしたい.
Chromeのプラグインは目に見える部分以外にバックグラウンドの見えないおエージ存在し,ストレージはそちら側にあるのでどうも直接は手出しができそうにない.
そこで,background.jsの中の refreshSiteinfo を一時的に書き換えて,常にネットワークからデータを読み込むようにして無理矢理更新させたところ,認識するようになった.
{
"name": "Django Snippets Taglist",
"version": "1.0",
"description": "Autolod tag list",
"content_scripts": [
{
"matches": ["http://djangosnippets.org/tags/", "http://djangosnippets.org/tags/?page=*"],
"css": [ "djsnippets.css" ],
"js": ["jquery-1.4.2.min.js", "script.js"]
}
]
}
matchesで対象サイトを(複数)設定し,そのページで読み込ませたいcssとjavascriptファイルを指定すればよい.読み込ませるファイルはmanifest.jsonと同じディレクトリに入れる.
作成したら,「拡張機能」で「デベロッパーモード」を開き,「パッケージ化されていない拡張を読み込みます」でmanifest.jsonの入ったディレクトリを指定すれば登録される.
[メモ]
拡張機能中のスクリプトにはコンソールからはアクセス出来ないので,コンソールから変数の値をチェックしたり関数を呼び出したりできない.対象サイトのページをファイルに落とすなりしてローカルのテスト用HTMLを用意し,そのヘッダファイルを書き換えてcss/jsを読み込むようにするとコンソールからアクセスできるのでデバッグしやすい.
スクリプトの中にbreakpointを設定しておくと,breakした時はそのスクリプトの変数にアクセスできる.この方法で実行経路と値のチェックができる.
printfデバッグに近い方法として console.log() を使う方法がある.引数には文字列だけでなくオブジェクトを与えることができ,オブジェクトを与えた場合にはコンソール上でその内容にツリー形式でアクセスできる.
動作するようになったらパッケージを行う.「拡張機能」の「拡張機能のパッケージ化」からパッケージ化するディレクトリを指定するだけ.秘密鍵の部分は2回目以降(更新時)のみ入力する.最初は空欄にしておけば新たに生成される.
生成された *.crx をGoogle ChromeにDrag & Dropすれば普通の拡張としてインストールされる.
できたもの: djangosnippets.crx
やってること
- CSS: liタグが縦でなく横に並ぶように float: left に変更
- Javascript: Next 20< というリンクの先を読み込んでリストに追加することを400ms毎に繰り返す.
実際に動かしてみるとあまり感慨がない.(-_-)
最初に djangosnippets のタグページが使いづらいと感じた当時はタグがアルファベット順に出力されていた.しかも記号が入ったタグがあったために,ページをめくらないとまともなタグが見えない状態であった.しかし,現在はその点は改善されて使用頻度の高いタグが先頭に出るようになっている.
さて,ここまでやったところで単に次のリンクをたどるだけなら,普段使っている AutoPagerize で十分な気がしてきた.こちらは対象ページのパターン,たどるリンク,取り出す要素などを指定したSITEINFOを作るだけでOKのようだ.
SITEINFOでは対象要素をXPathで指定するようになっており,SITEINFOの作り方 ではFireBugを使うように指示されている.だが調べてみると Google ChromeのDeveloper Toolsの検索ボックスでXPathが使えるようだ.
試しにやってみる
ハイライトはされないようだが,該当する要素が見つかったかどうかはmatchesを見れば良く,また見つかった要素がDOMツリーで展開される.
さて,では実際にdjangosnippets.org/tags/ を対応させてみることにする.
まず,テスト的に対応させる方法についてFirefoxについては記述があるのだが,Chromeについては記述がない.調べたところ,AutoPagerize のメインファイルである autopagerize.user.js 中の SITEINFO に直接記述して,Google Chromeを再起動すれば読み込まれることが分かった.autopagerize.user.js はC:\Documents and Settings\
{
url: 'http://djangosnippets.org/tags/',
nextLink: '//p[@class="pagination"]/a[contains(text(),"Next")]',
pageElement: 'id("main")/ul',
exampleUrl: 'http://djangosnippets.org/tags/',
}
この状態で http://djangosnippets.org/tags/ を開くと,次々とページがめくられてゆく.
最初,nextLinkとpageElementを誤って逆に書いてしまったのだが,その時はコンソールログにエラーメッセージが表示された.ただ,その内容は「undefinedにmatchメソッドがない」という物だったので原因が分かるまでに時間を要した.(リンクであるnextLinkの href を読み取ろうとするが,それが存在しないとundefinedとなり,次の行でエラーとなっていた.)
さて,この情報をAutoPagerizeのデータベース に登録するとみんなが使えるようになる.OpenIDを使ってログインした後に「アイテム追加」を行えば登録ができる.登録するとJSONでそのデータが直ちに利用可能となる.
ちなみに,OpenIDには便利なボタンが用意されていないので例えばGoogleの場合は https://www.google.com/accounts/o8/id のようにEndPpint URLを入力する必要がある.
さて,サーバへの登録を行っても自分のブラウザでは有効化されない.調べてみるとローカルストレージにキャッシュを持っていて,1日以上経たないと更新されない.これでは動作テストでは困るので何とか無理矢理キャッシュをクリアしたい.
Chromeのプラグインは目に見える部分以外にバックグラウンドの見えないおエージ存在し,ストレージはそちら側にあるのでどうも直接は手出しができそうにない.
そこで,background.jsの中の refreshSiteinfo を一時的に書き換えて,常にネットワークからデータを読み込むようにして無理矢理更新させたところ,認識するようになった.
Comments